
 智东西
智东西
编译 | 陈骏达
裁剪 | Panken
智东西2月18日报说念,今天地午,DeepSeek团队发布一篇新论文,先容了一种编削的稀少提防力机制NSA,可用于超快速的长陡立文检会与推理。NSA以性价比极高的格式,生分地在检会阶段应用稀少性,在训推场景中均齐全速率的昭着擢升,阑珊是在解码阶段齐全了高达11.6倍的擢升。
让东说念主目下一亮的是,DeepSeek首创东说念主兼CEO梁文锋此次出目前了合著明单之中,在作家名次中位列倒数第二。这意味着他看成神志管制者,参与了一线的酌量责任。另外,这篇论文的第一作家Jingyang Yuan是在实习时分完成的这项酌量。

据DeepSeek先容,NSA具有三大中枢组件:动态分层稀少政策、粗粒度token压缩、精粒度token采取。通过三大组件的互助,既擢升了遵守,也保留了模子对全局长陡立文的感知才能和局部精准性。
这一机制成心针当代硬件进行优化假想,原生搭救模子检会,在加快推理的同期镌汰预检会老本,对性能也无昭着影响。接受NSA机制的模子在通用基准、长陡立文任务和基于辅导的推理上,与全提防力模子相配或发扬更优。
在8卡A100操办集群上,NSA的前向传播和反向传播速率分歧比全提防力快9倍和6倍,由于减少了内存拜访量,NSA在长序列解码时相较于全提防力模子速率权臣擢升。
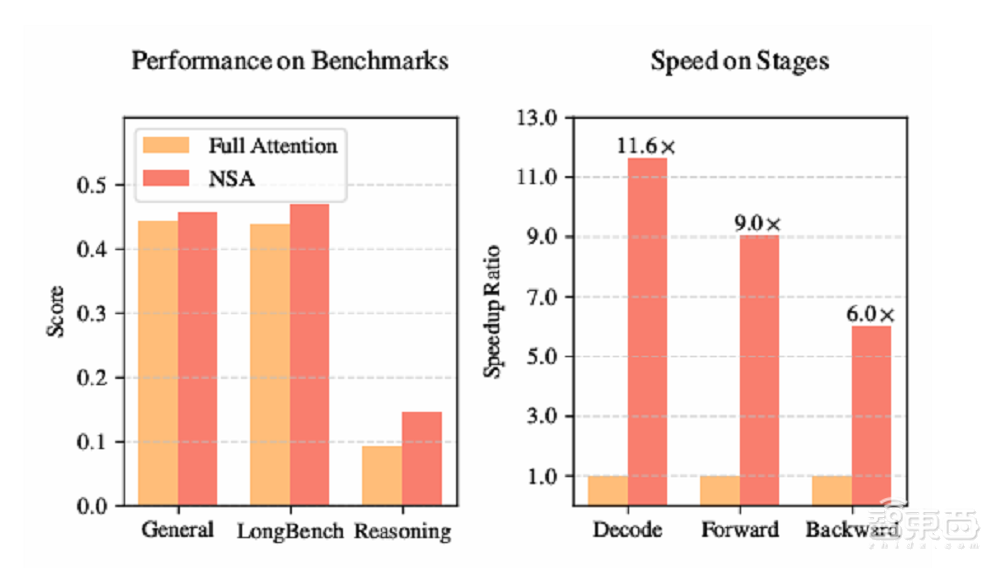
▲NSA在部分测试上的发扬(图源:DeepSeek)
论文运动:arxiv.org/abs/2502.11089
一、现存稀少提防力机制存在昭着残障,DeepSeek但愿填补空缺
长文本建模是下一代讲话模子的关节才能,但传统提防力机制的高复杂度操纵了其在长序列上的应用。
举例,在解码64k长度的陡立文时,提防力操办占据了总延长的70%至80%。因此,稀少提防力机制应时而生,通过采取性操办关节的查询键对来减少操办支出。
然则,尽管很多稀少提防力次序在表面上减少了操办复杂度,但这些次序在本色推理中未能权臣镌汰延长。
一些次序仅在自追溯解码阶段应用稀少性,而预填充阶段仍需进行密集操办(如H2O);另一些次序仅温和预填充阶段的稀少性(如MInference),导致在某些责任负载下无法齐全全阶段加快。
还有部分稀少次序无法相宜当代高效的解码架构(如MQA和GQA),导致KV缓存拜访量仍然较高,无法充分施展稀少性上风。
此外,现存的稀少提防力次序大多仅在推理阶段应用稀少性,穷乏对检会阶段的搭救。
NSA旨在通过针对硬件特质的推理加快和适用于检会的算法假想,填补这一空缺。DeepSeek推出NSA主要但愿处分两大问题:
一是过后稀少化导致性能退化,如预检会模子的检索头易被剪枝;
二是现存稀少次序难以莽撞长序列检会的遵守需求。现存次序存在非可检会组件和低效反向传播等问题,收敛了高效检会和长陡立文模子的发展。
二、软硬件协同深度优化,无穷贴近操办强度最优解
NSA的中枢念念想是通过动态分层稀少政策,鸠合粗粒度的token压缩和细粒度的token采取,以保留全局陡立文感知才能和局部精准性。
下方是NSA架构的概览,左侧,NSA将输入序列通过三个并行的提防力分支处理:压缩提防力(compressed attention)、采取性提防力(selected attention)和滑动窗口提防力(sliding attention)。右侧是对每个分支产生的不同提防力模式的可视化。绿色区域暗意需要操办提防力分数的区域,而白色区域暗意不错跳过的区域。
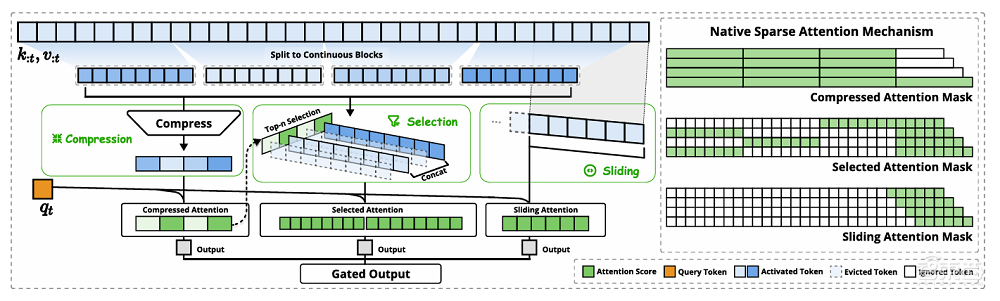
▲NSA架构概览(图源:DeepSeek)
其中,压缩提防力通过将键(key)和值(value)团员成块(block)级暗意来捕捉粗粒度的语义信息。这种压缩暗意简略捕捉更粗粒度的高层语义信息,并安定提防力操办的包袱。
不外,仅使用压缩后的键(key)和值(value)可能会丢失弥留的细粒度信息,DeepSeek引入了采取性提防力,通过块采取机制保留弥留的细粒度信息。
他们给每个块分拨了弥留性分数,字据块的弥留性分数采取名次前n的块,并将这些块中的标记用于提防力操办。这种次序在保留关节信息的同期,权臣镌汰了操办包袱。
在提防力机制中,局部模式继续会快速相宜并主导学习经由,可能会收敛模子从压缩和采取token中灵验学习。滑动窗口提防力不错陈诉这一问题,通过专注于局部陡立文信息,防止模子过度依赖局部模式。
为了齐全高效的稀少提防力操办,NSA还针对当代硬件进行了优化。
具体来看,DeepSeek在Triton上齐全了硬件对皆的稀少提防力内核。鉴于多头自提防力(MHA)内存密集且解码遵守低,他们专注于分享KV缓存的架构,如分组查询提防力(GQA)和多查询提防力(MQA),这些架构与现时启程点进的LLMs一致。
DeepSeek的关节优化政策是接受不同的查询分组政策,通过以下关节性格齐全了近乎最优的操办强度均衡:
1、以组为中心的数据加载:在每个内轮回中,加载组内系数头的查询阑珊分享的稀少KV块索引。
2、分享KV加载:在内轮回中,一语气加载KV块以最小化内存加载。
3、网格轮回调换:由于内轮回长度在不同查询块中实在通常,将查询/输出轮回放在Triton的网魄力度器中,以简化和优化内核。
三、高出多款基线模子,检会提速6-9倍、推理最高提速11.6倍 为测试NSA机制在本色检会、推理场景中的发扬,DeepSeek用现时启程点进的LLM的常见实际,使用了一个鸠合分组查询提防力(GQA)和夹杂巨匠(MoE)的主干架构看成样本模子。这一模子总参数目为27B,其中3B为活跃参数。
在这一模子的基础上,DeepSeek使用了NSA、全提防力以阑珊它提防力机制,并进行了评估。
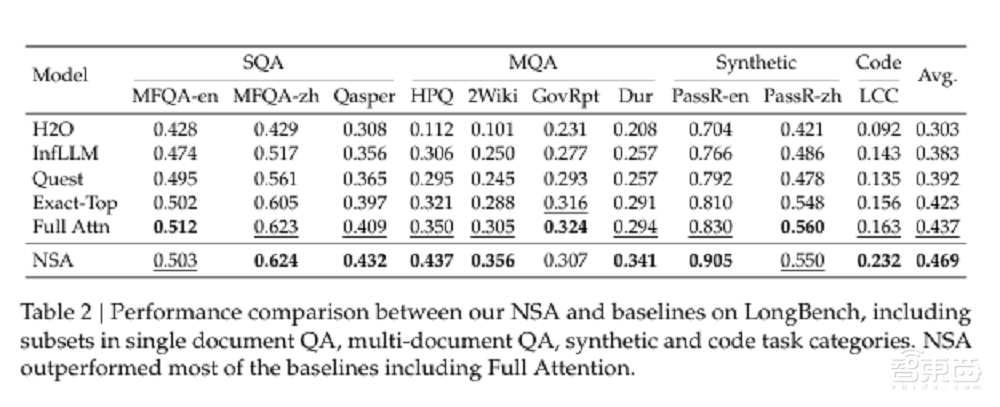
在多个通用基准测试中,接受NSA的模子尽管具有稀少性,但其总体性能优于系数基线模子,包括全提防力模子,在9神志的中有7项发扬最好。
▲接受不同提防力机制的模子在多个通用基准测试上的发扬(图源:DeepSeek)
NSA在较短序列上可能未能充分施展其遵守上风,但其性能照旧强劲。值得提防的是,NSA在推理关连基准测试中取得了权臣擢升,这标明NSA的预检会机制有助于模子开发成心的提防力机制,能迫使模子专注于最弥留的信息,通过过滤掉无关的提防力旅途中的噪声,潜在地擢升了性能。
在长陡立文任务中,NSA在64k陡立文的“大海捞针(neddle in a haystack)”测试中齐全了超强的的检索精度。这获利于其分层稀少提防力假想,通过粗粒度的压缩token齐全高效的全局陡立文扫描,并通过细粒度的采取标记保留关节信息,从而在全局感知和局部精准性之间取得均衡。
 ▲大海捞针测试结果(图源:DeepSeek)
▲大海捞针测试结果(图源:DeepSeek)
在LongBench上,NSA在多跳QA任务和代码理除名务中发扬优于系数基线,还流泄漏在复杂长文本推理任务上的上风。这些结果标明,NSA的原生稀少提防力机制不仅擢升了模子性能,还为长文本任务提供了更优的处分决策。
NSA机制还能与推理模子进行鸠合,适配前沿的后检会格式。DeepSeek使用了从DeepSeek-R1蒸馏取得的常识和监督微调(SFT)的格式,使接受NSA的模子在32k长度的数学推理任务上取得链式数学推理才能。
实验中,NSA-R(稀少提防力变体)和全提防力-R(基线模子)在具有挑战性的AIME 24基准测试上进行了对比。结果流露,NSA-R在8k和16k陡立文开拓下均权臣优于全提防力-R(分歧逾越0.075和0.054),考证了其在复杂推理任务中的上风。
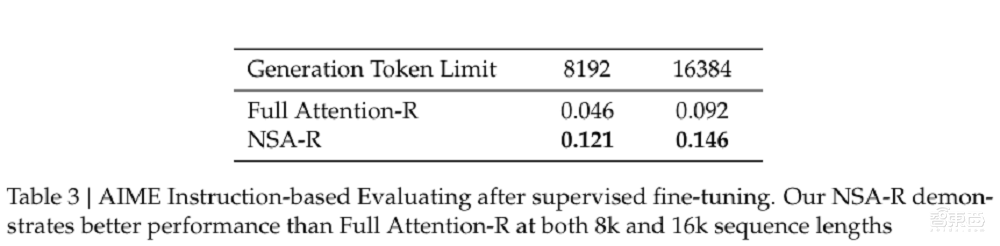
▲NSA-R(稀少提防力变体)和全提防力-R(基线模子)在AIME上的发扬(图源:DeepSeek)
DeepSeek还在8-GPU A100系统上,对NSA的操办遵守与全提防力机制进行了对比。
在检会速率方面,跟着陡立文长度的增多,NSA的加快效果愈发权臣。在64k陡立文长度时,NSA的前向传播速率擢升了9倍,反向传播速率擢升了6倍。
这种加快主要获利于NSA的硬件对皆假想:块状的内存拜访模式通过并吞加载最大化了Tensor Core的运用率,内核中紧密的轮回调换排斥了冗余的KV传输。
在解码速率方面,提防力机制的解码速率主要受限于KV缓存加载的内存瓶颈。跟着解码长度的增多,NSA的延长权臣镌汰,在64k陡立文长度时齐全了高达11.6倍的速率擢升。这种内存拜访遵守的上风跟着序列长度的增多而愈加昭着。
结语:DeepSeek合手续给开源AI惊喜
尽管NSA取得了权臣的效果,但DeepSeek酌量团队也指出了一些可能的编削地方。举例,进一步优化稀少提防力模式的学习经由,以及探索更高效的硬件齐全格式。
正如DeepSeek之前发布的系数工夫论说那样,这篇详解NSA机制的论文内容翔实,对NSA机制中触及的工夫细节阐释明晰,可操作性强欧洲杯体育,是DeepSeek给开源AI酌量孝顺的最新效果。